

Understanding The Decoder (Part III)
Decoding the Encoder: A Deep Dive into Transformer Architecture

This article is the third (and last!) part of a three-part deep dive into one of the most revolutionary AI architectures of our time:
Transformers.
Here’s what’s coming your way:
✅ Week 1: Understanding the Transformers architecture → Link
✅ Week 2: The Encoder → Link
✅ Week 3: The Decoder → Link
Understanding the Decoder - Part III
The decoder’s primary role is to generate text sequences step by step, transforming encoded information into meaningful output.
Structurally, the decoder mirrors the encoder in many ways—it consists of multiple layers, each containing:
Two multi-headed attention mechanisms
A pointwise feed-forward layer
Residual connections and layer normalization after each sub-layer
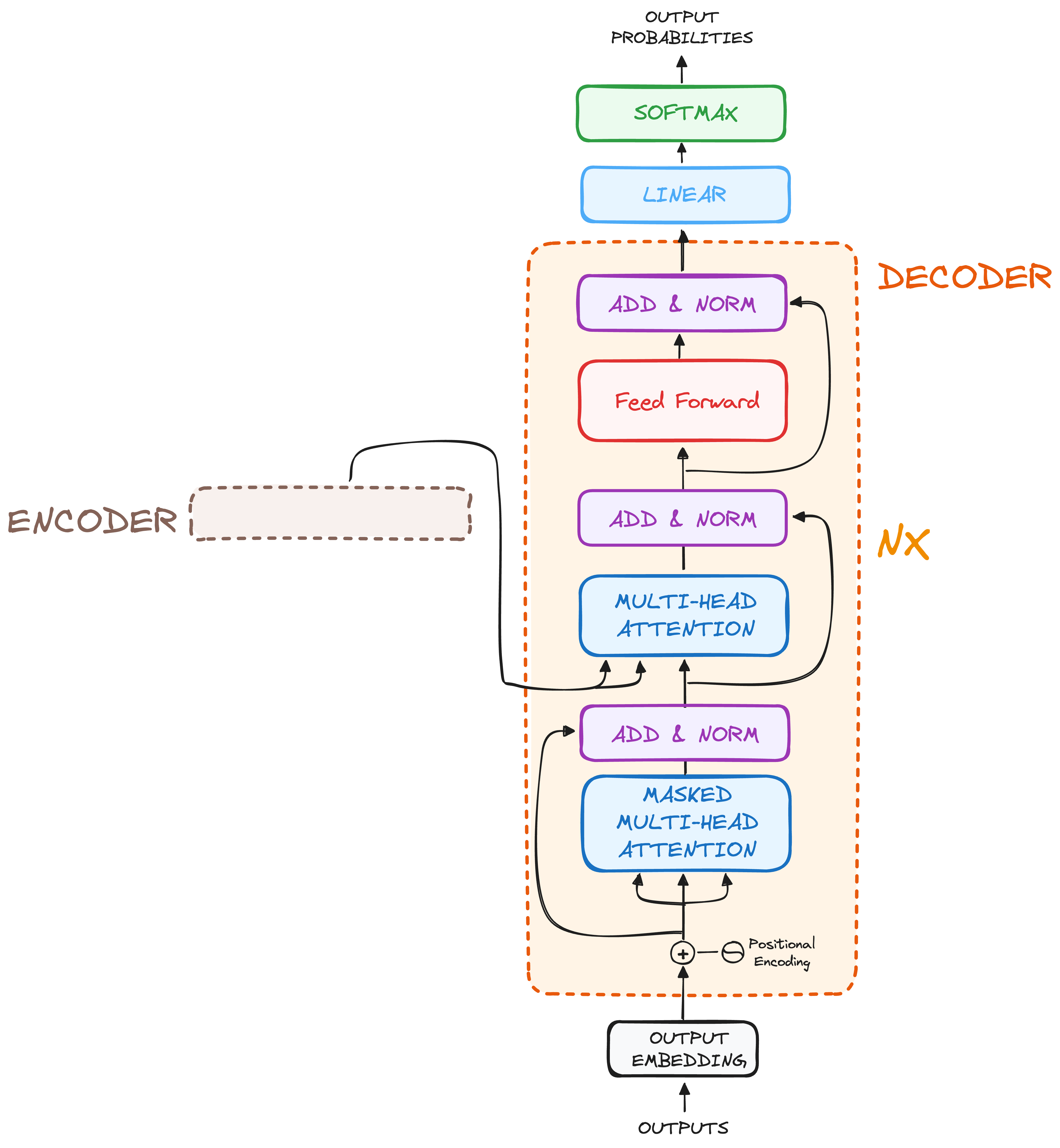
However, there’s a key difference: while the encoder’s attention focuses only on the input sequence, the decoder’s attention is split into two distinct tasks:
Masked Self-Attention – Ensures that the decoder can only attend to previous tokens, preventing it from “cheating” by looking ahead.
Encoder-Decoder Attention – Allows the decoder to focus on relevant encoded information, guiding the text generation process.
The final step in the decoder is a linear layer, which acts as a classifier, followed by a softmax function to assign probabilities to possible next words.
The Transformer decoder operates autoregressively—meaning it generates one token at a time, starting with a special start token.
At each step, it takes into account previously generated tokens and encoder outputs to predict the next word.
This process repeats until it generates a special end token, signaling that the sequence is complete.
Through this step-by-step decoding process, the model crafts coherent, context-aware text.
And this is precisely… the foundation of AI-powered language generation.
Before starting, here you have the full-resolution cheatsheet 👇🏻

And now… let’s break it down!
STEP 1 - Target Sequence Embedding
The decoder starts by embedding the target sequence—the sequence of tokens that have been generated so far. This process is similar to the input embeddings in the encoder but applies to the decoder’s inputs instead.
💡 Key Difference:
The encoder processes the full input sequence at once.
The decoder works autoregressively, meaning it processes tokens one by one, using previously generated tokens as inputs.
(⚠️ Missed Part 1 and Part II? Check them out to get the full picture 👇🏻)


STEP 2 - Positional Encoding
Since Transformers lack recurrence, they rely on positional encodings to retain word order information. Just like in the encoder, the decoder adds sine and cosine-based positional encodings to its embedded inputs.
These enriched vectors are then fed into the first multi-head attention layer, where the model computes attention scores specific to the decoder’s input.
STEP 3 - Stack of Decoder Layers
Like the encoder, the decoder consists of stacked identical layers (6 in the original Transformer). Each decoder layer contains three main sub-components:
3.1 Masked Self-Attention Mechanism
🔍 What’s different from the encoder?
In the encoder, self-attention allows each word to attend to all words in the sequence.
In the decoder, self-attention is masked, meaning each word can only attend to previous words—not future ones.
For example, when predicting the word “are”, the model must not see “you” before generating its output.
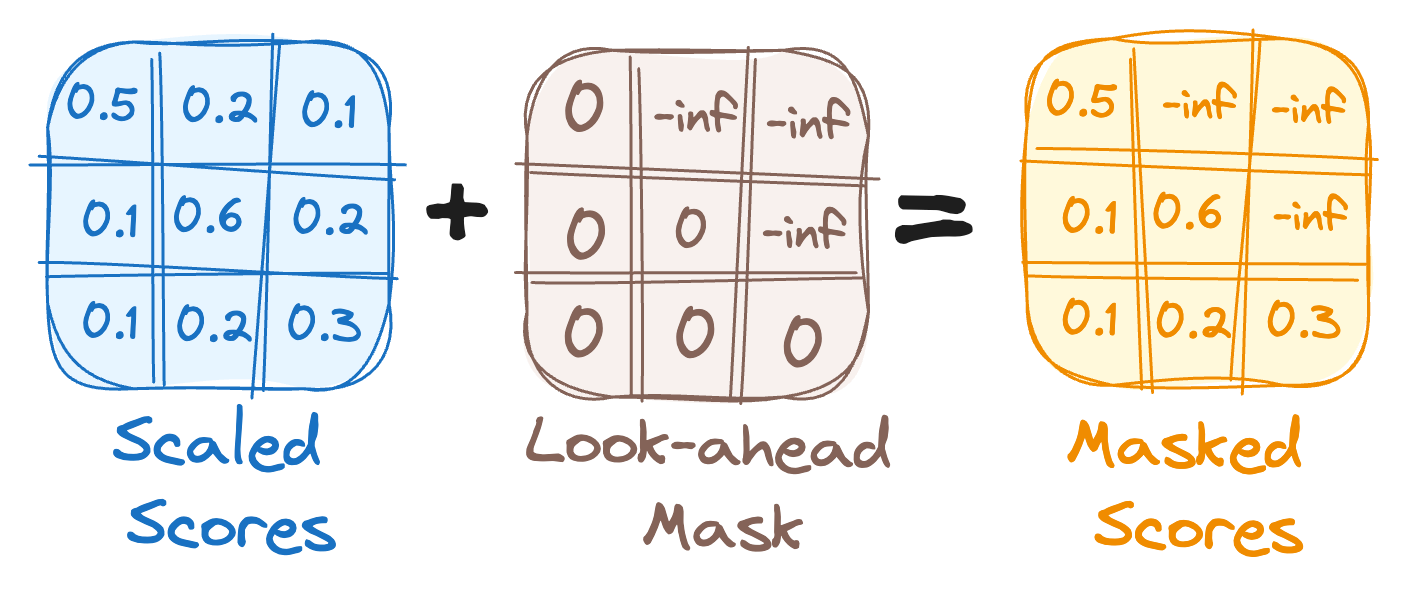
✅ How does masking work?
A look-ahead mask is applied, setting attention scores for future words to negative infinity, effectively blocking them from being considered in the computation.
3.2 Encoder-Decoder Attention (Cross-Attention)
This is where the decoder interacts with the encoder’s output.
✅ How it works:
The queries come from the decoder’s previous layer.
The keys and values come from the encoder’s final output.
This mechanism allows the decoder to focus on relevant parts of the encoded input, helping it generate more accurate and context-aware predictions.
Decoder’s workflow. Encoder-Decoder Attention.
💡 Why is this important?
Cross-attention helps bridge the gap between encoded representations and the decoder’s partial sequence generation, ensuring that the generated output remains aligned with the original input.
3.3 Feed-Forward Neural Network
Each decoder layer includes a fully connected feed-forward network, applied independently to each position in the sequence.
It consists of:
A first linear transformation (expanding features).
A ReLU activation function (introducing non-linearity).
A second linear transformation (projecting back to the embedding size).
This enhances feature extraction before passing information to the next decoder layer.
3.4 Normalization and Residual Connections
Like in the encoder, each sub-layer (self-attention, cross-attention, and feed-forward network) is followed by:
✅ Residual connections, allowing gradients to flow efficiently.
✅ Layer normalization, stabilizing training and ensuring smoother learning.
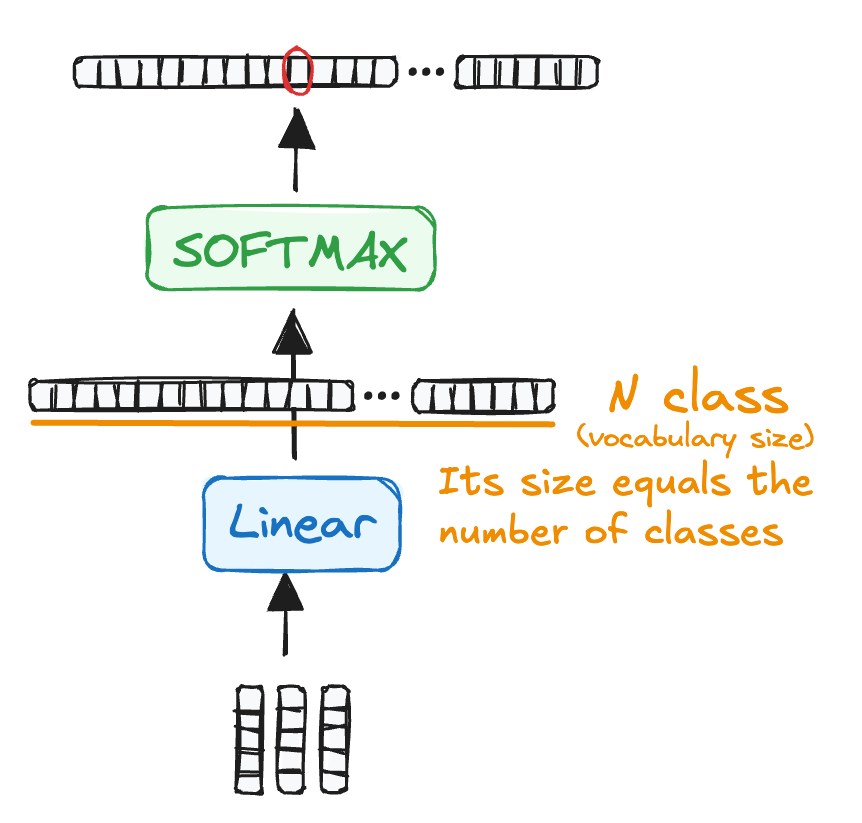
STEP 4 - Linear Classifier and Softmax for Output Generation
At the final stage, the decoder’s processed output is passed through a linear layer, which acts as a classifier.
✅ How does it work?
The classifier’s size matches the total vocabulary size (e.g., 50,000 words in GPT-3).
The output is a vector of probability scores, where higher scores indicate more likely words.
These scores are then fed into a softmax function, which converts them into a probability distribution.
💡 Final word prediction:
The word with the highest probability is selected as the next token in the sequence.
STEP 5 - Final Output and Autoregressive Decoding
The decoder reuses its own generated outputs as inputs for the next step, continuously predicting tokens until it generates a special end token.
✅ Key Takeaways:
The model processes one token at a time, making it autoregressive.
Each prediction is based on previous tokens and the encoder’s output.
The process continues iteratively until an end token signals the completion of the sequence.
💡 More Layers = Better Context Understanding
The Transformer stacks multiple decoder layers, extracting diverse attention patterns across multiple attention heads, leading to more accurate and coherent text generation.
Final Architecture
The complete Transformer architecture, as introduced in the original paper, consists of stacked encoder-decoder layers working in harmony to process inputs and generate outputs efficiently and it looks as follows 👇🏻
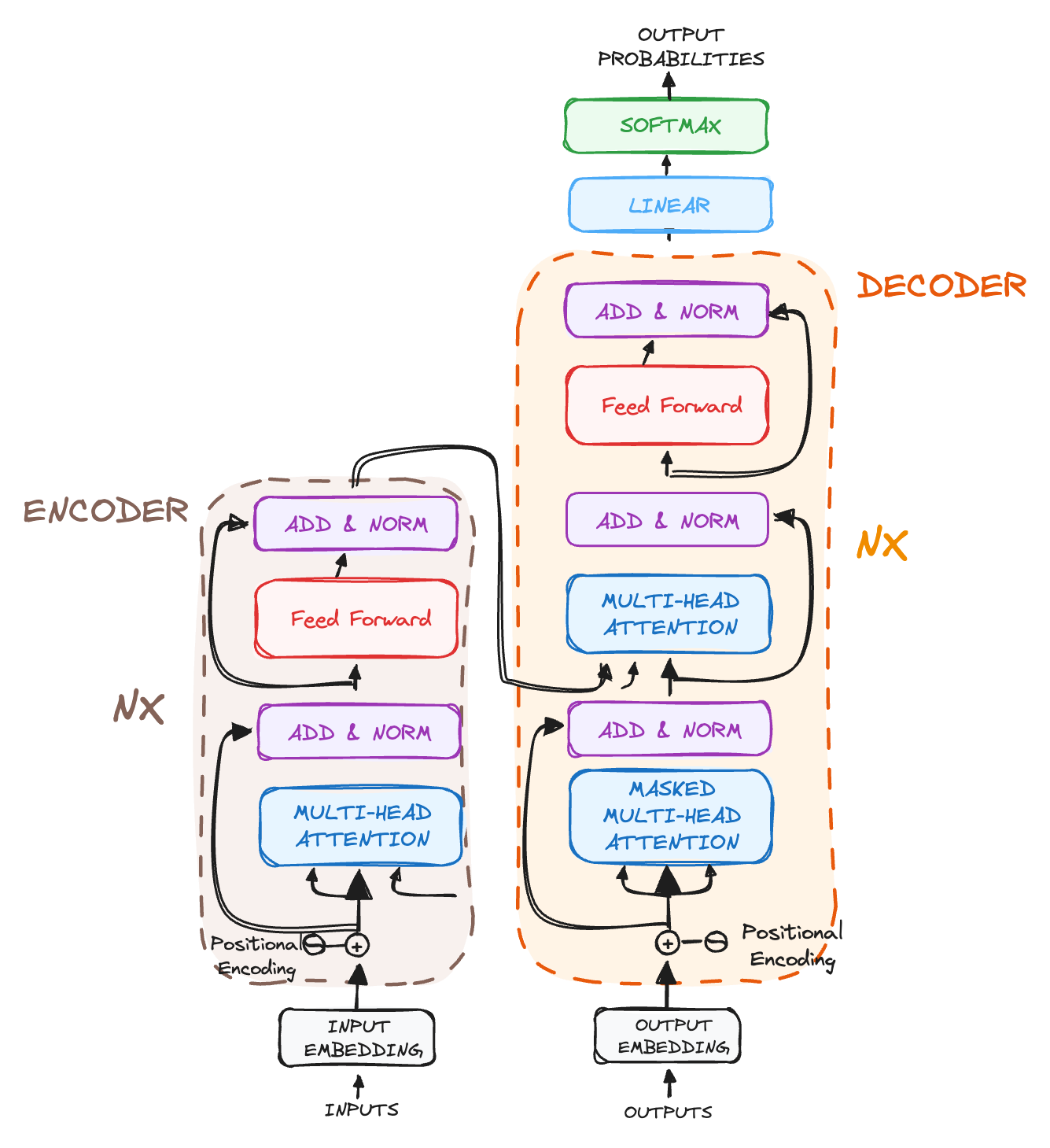
This powerful structure forms the foundation of modern AI models like GPT, Deepseek, and Gemini!
—Josep
Are you still here? 🧐
👉🏻 I want this newsletter to be useful, so please let me know your feedback!
Before you go, tap the 💚 button at the bottom of this email to show your support, it really helps and means a lot!
Any doubt? Let’s start a conversation! 👇🏻
Want to get more of my content? 🙋🏻♂️
Reach me on:
LinkedIn and X (Twitter) to get daily posts about Data Science.
My Medium Blog to learn more about Data Science, Machine Learning, and AI.
Just email me at rfeers@gmail.com for any inquiries or to ask for help! 🤓